Conversations With Datomic - Part 3

This is a continuation of the first and second conversations in which topics such as creating databases, learning facts, querying, and time traveling were discussed. Today’s topics include architecture, caching, and scaling.
Human: Hello again Datomic. Ready to talk again?
Datomic: Sure. I think you wanted to ask me some questions about how I would fit in with your other systems.
Human: Yes. Like I was saying earlier, I think your abilities to learn facts, reason about them, and keep track of the history of all those facts is really great. I am interested in having you work with me every day, but first I want to understand your components so that I can make sure you are a good fit for us.
Datomic: I would be happy to explain my architecture to you. Perhaps showing you this picture is the best way to start.
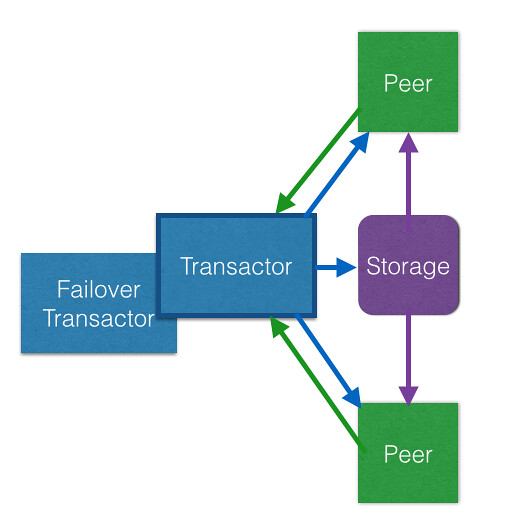
I am made of three main parts: my transactors, my peers, and my storage.
Human: What is a peer?
Datomic: A peer is an application that is using the peer library. In our last conversations, we were talking through the Clojure api with datomic.api. The application, or process, that is running this api is called a peer. There can be many of these, all having conversations with me.
Human: The peers then talk to your transactor?
Datomic Yes. The peers talk to my transactor whenever you call transact with the peer library. It is the central coordinator between all the peers and processes the requests using ACID transactions, and then sends the facts off to storage.
Human: Could you remind me what ACID stands for again? I always forget. The first one is Atomic right?
Datomic: That is right. I am Atomic in that every transaction you send to me is all or nothing. If for some reason, one part of it fails, I will reject the entire transaction and leave my database unchanged.
The C is for Consistency. This means that I provide every peer with a consistent view of facts over time and transactions. I provide a global ordering of transactions across all the peers with my transactor and peers will always see all the transactions up to their current time without any gaps.
Human: What if a peer is behind the global time? How do they catch up to know about the new facts that were transacted by a different peer?
Datomic: After one peer sends me a successful transaction with some new facts, I will notify all the peers about them.
Human: Cool. That takes care of the A and C in ACID. What about the I?
Datomic: It stands for Isolated. It makes sure that even through there are many peers having conversations with me, transactions are executed serially. This happens naturally with my transactor. Since there is only one transactor, transactions are always executed serially.
Human: In the picture, why are there are two transactors then?
Datomic: Oh, that is for High Availability. When I startup my system, I can launch two running transactors, but hold one in reserve. Just on the off chance something happens to the main one, I will swap in the failover one to keep things running smoothly.
The final D in ACID is for Durability. Once a transaction has been committed by my transactor, it is shipped off to storage for safe keeping.
Human: What exactly is this storage?
Datomic: Instead of storing datoms, I send segments, which are closely related datoms, to storage. I have quite a few options for storage:
- Dev mode - which just runs within my transactor and writes to the local file system.
- SQL database
- DynamoDB
- Cassandra
- Riak
- Couchbase
- Infinispan memory cluster
Human: Which one is the best to use?
Datomic: The best one to use is the one that you are already have in place at work. This way, I can integrate seamlessly with your other systems.
Human: Oh, we didn’t really talk about caching. Can you explain how you do that?
Datomic: Certainly. It is even worth another picture.
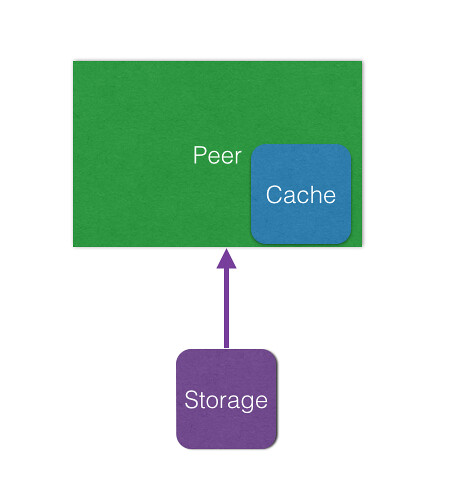
Each peer has a its own working set of recent datoms along with a index to all the rest of the datoms in storage in memory. When the peer has a query for a datom, it first checks to see if it has it locally in its memory cache. If it can’t find it there, then it will ask for a segment of that datom from storage. Storage will return that datom along with other related datoms in that segment so that the peer can cache that in memory to make it faster for the next query.
Human: That seems really different from other databases, where the client constantly requests queries from a server.
Datomic: Yes. When most questions can be answered from the local memory, responses are really fast. You don’t need to hit storage unless you really need too. You can even add an extra layer of caching with memcached.
Human: That sounds great. I can’t wait tell you about all of our data. We talked a bit about your querying ability earlier, can you do the same queries that our other standard relational databases do, like joins?
Datomic: Oh yes. In fact, with me, you don’t need to specify your joins explicitly. I use Datalog, which is based on logic, so my joins are implicit. I will figure out exactly what I need to put together to answer your query without you having to spell it out for me.
Human: Ok. I know that I can map some of my data that is already in other database tables to you. What about other types of irregular data, like graphs, or sparse data.
Datomic: I am actually very proud of my data model. It is extremely flexible. Since I store things on such a granular datom level, you don’t need to map your logical data model to my physical model. I can handle rectangular table shaped data quite happily along with graph data, sparse data, or other non-rectangular data.
Human: That sounds great. What do I need to know about your scaling?
Datomic: I really excel at reads. All you have to do is elastically add another peer to me for querying. I am not really a good fit for write scale, like big data, or log file analysis. You will find me most happy with data that is valuable information of record and has history that is important, like transaction, medical, or inventory data. I am also really good at being flexible for development and operations since I can use many different types of storage. I have worked with many web and cloud apps.
Human: Thanks for answering all my questions. I think you might fit in quite well with our other systems.
Datomic: Great!
Human: One more thing, this conversation has been great, but do you have any training resources for me and my other human coworkers?
Datomic: Sure thing. There are a few really good resources on the Datomic Training Site. I would suggest watching the videos there and pairing them with:
- The slides for the videos which have the labs to work through form the videos.
- The Day of Datomic Repo which has lots of great examples to play with.
- Tne Datomic Development Resources, which include the docs on the Clojure API
Also, if you want to confirm that your data is good fit for me, I suggest you describe your data to the Datomic Google Group. They are nice and knowledgeable group of humans.
Human: Thanks again Datomic! I will grab another cookie and check it out!
Datomic: What is it with humans and cookies?…