We humans are quite wonderful. We do amazing things every day without even realizing it. One of them, you are doing right now. You are reading text. Your brain is taking these jumbles of letters and spaces in this sentence, which in linguist terms is called an utterance, and making sense out of it. The individual meanings of sentences might be quite complex.
Take for example the utterance, “I like cheese”. To understand it properly, you need to know the meanings of the individual words. In particular, you would need to know that cheese is a tasty food stuff that is made from milk. This would be a detailed and full understanding. But there is a higher level of understanding that we can look at called Speech Acts.
Speech Acts are way of classifying our communication according to purposes. We perform speech acts when we ask questions, make statements, requests, promises, or even just say thanks. These speech acts cross languages. When I ask a question in English, it is the same speech act as if I ask it in French. In fact, if we were to travel to another planet with aliens, we can assume if they had a language, it would involve speech acts. It should be no surprise then, to communicate effectively with machines, it will have to understand speech acts.
To explore this communication we are going to consider only three speech acts:
- Statements - “I like cheese.”
- Questions - “How do you make cheese?”
- Expressives - “Thank you”
Our goal is to have our program be able to tell the difference between these three speech acts - without punctuation.
Why not use punctuation? If you are having a conversation with a human over Slack or some other chat channel, you may or may not put in a question mark or period. To have a computer be able to converse as naturally with a human as another human, it will have to understand the speech act without the aid of punctuation.
Generally, we want to have the computer:
- Read in an utterance/text that may or may not have punctuation.
- Classify whether the result is a statement, question, or expressive.
To tackle this problem, we are going to have to break this up into two main parts. The first is parsing the text and annotating it with data. The second is to classify the text based on the data from the parsing.
Parsing and Annotating Text with Stanford CoreNLP
The Stanford CoreNLP is considering the state of the art for POS, (Part of Speech), tagging and other linguistic annotations. It also is a Java library, so very easy to use from Clojure.
Here we are using a simple wrapper library called stanford-talk to take in some text and process it. The result is a list of tokens for each word in the :token-data map. Each token is annotated with the POS tag. There is a lot more data in the annotations that we can look at to give us insight into this text. But, to keep things simple, we are just going to look at the POS speech tag at the moment.
(process-text "I like cheese")
;{:token-data
; ({:sent-num 0, :token "I", :pos "PRP", :net "O", :lemma "I", :sentiment "Neutral"}
; {:sent-num 0, :token "like", :pos "VBP", :net "O", :lemma "like", :sentiment "Neutral"}
; {:sent-num 0, :token "cheese", :pos "NN", :net "O", :lemma "cheese", :sentiment "Neutral"}),
; :refs [[{:sent-num 0, :token "I", :gender "UNKNOWN", :mention-type "PRONOMINAL", :number "SINGULAR", :animacy "ANIMATE"};]]}
So the text “I like cheese” has the following POS tags list of all POS tags:
- I = PRP Personal Pronoun
- like = VBP Verb, non-3rd person singular present
- cheese - Noun, singular or mass
This is great. We have some data about the text we can analyze. The next thing to do is to figure out how to classify the text based on this data.
Classification with Weka
Weka is a collection of machine learning algorithms. There is a program for interactive exploration of data sets, as well as a java library so you can use it programatically. Speaking of data sets, we need some. Just having one sentence about liking cheese is not going to get us very far with any machine learning.
So where can you go to get conversational questions and statements on the internet? Well, one place that is pretty good for that is answers.com. We can scrape some pages for questions and answers. Enough so that we can collect and cleanup some input files of
- ~ 200 statements
- ~ 200 questions
The expressives were a bit more difficult. Let’s just make a list of about 80 of them.
Now, we have a list of text data. We need to decide on some features and generate some input files to train the classifiers on.
Choosing Features for Classification
First, what is a feature? A feature is some sort of encoding of the data that the computer is going to consider for classification. For example, the number of nouns in a sentence could be a feature. There is a whole field of study dedicated to figuring out what the best features for data for machine learning are. Again, to keep things simple, we can take an educated guess on some features based on a good paper:
- Sentence length
- Number of nouns in the sentence (NN, NNS, NNP, NNPS)
- If the sentence ends in a noun or adjective (NN, NNS, NNP, NNPS, JJ, JJR, JJS)
- If the sentence begins in a verb (VB, VBD, VBG, VBP, VPZ)
- The count of the wh, (like who, what) markers (WDT, WRB, WP, WP$)
We can now go through our data file, generate our feature data, and output .arff file format to ready it as training file for weka.
Raw question file example:
What is floater exe
Is bottled water or tap water better for your dog
How do you treat lie bumps on the tongue
Can caffeine be used in powder form
Arff file with features
@relation speechacts
@attribute sen_len numeric
@attribute nn_num numeric
@attribute end_in_n numeric
@attribute begin_v numeric
@attribute wh_num numeric
@attribute type {assertion,question,expressive}
@data
4,2,1,0,1,question
10,4,1,0,0,question
9,3,1,0,1,question
7,3,1,0,0,question
Now that we have our input file to training our machine learning algorithms, we can start looking at classifiers.
Choosing the Classifier
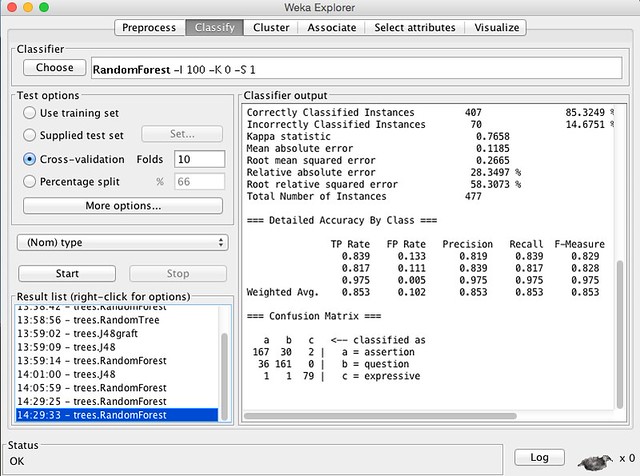
Using the weka explorer, we can try out different classification models. For this data, the best one seems to be the Random Forest. In the explorer, it beat out Naive Bayes and J48. It is also worth mentioning that we are not using a separate source of test data, we are cross validating on the original training set. If we wanted to be more rigorous, we could collect more data and cut it in half, using one set for the training and one set for the testing.
Now that we have a classifier, we can create some Clojure code with the java library to use it.
Using the Weka Classifier from our Clojure Code
After importing the needed Java classes into our Clojure code, we can create the Random Forest classifier.
(def classifier (new RandomForest))
We then create a function that will load our arff input file as a datasource
(defn get-datasource [fname]
(new ConverterUtils$DataSource
(.getResourceAsStream (clojure.lang.RT/baseLoader) fname)))
And another uses it to train the classifier, returning a map of the evaluator and data that we will need for our predictions.
(defn train-classifier [fname]
(let [source (get-datasource fname)
data (.getDataSet source)
_ (.setClassIndex data (dec (.numAttributes data)))
_ (.buildClassifier classifier data)
e (new Evaluation data)]
(.crossValidateModel e classifier data (.intValue (int 10)) (new Random 1) (into-array []))
(println (.toSummaryString e))
{:evaluator e
:data data}))
Now, we need to be able to ask about a classification for a particular instance of new data. This is going to be where we are parsing new text and asking for an answer from our trained model. To do this, we need to generate an instance for the evaluation to look at. It is constructed from numbers in the same order as our arff file. The exception is that we are not going to provide a value for the final field of the speech act type. We will assign that to the a missing value.
(defn gen-instance [dataset [val0 val1 val2 val3 val4]]
(let [i (new Instance 6)]
(doto i
(.setValue 0 (double val0))
(.setValue 1 (double val1))
(.setValue 2 (double val2))
(.setValue 3 (double val3))
(.setValue 4 (double val4))
(.setValue 5 (Instance/missingValue))
(.setDataset dataset))))
Now we can use this function in a prediction function to get our answer back
(defn predict [ev d vals]
(let [v (.evaluateModelOnce ev classifier (gen-instance d vals))]
(case v
0.0 :statement
1.0 :question
2.0 :expressive)))
Calling the predict function would look something like:
(def results (train-classifier "speech-acts-input-all.arff"))
(def predictor (:evaluator results))
(def data (:data results))
(predict predictor data [1 1 1 0 0])
;; -> :expressive
Now that we have the parsing piece and the classification piece, we can put everything together.
Putting it all together
We finally have all the details we need write a classify-text function.
(defn classify-text [text]
(let [stats (parser/gen-stats text)
features [(:sen-len stats)
(:nn-num stats)
(:end-in-n stats)
(:begin-v stats)
(:wh-num stats)]]
(weka/predict predictor data features)))
(classify-text "I like cheese")
;; -> :statement
(classify-text "How do you make cheese")
;; -> :question
(classify-text "Right on")
;; -> :expressive
Yea! It worked. We finally have something that will read in text and tell us its best guess of a speech act, all without punctuation. Let’s quickly review what we have done.
Summary
- Gather data sets of statements, questions, and expressives
- Parse text and annotate it with POS tags using Stanford CoreNLP
- Choose features of the data to analyze and generate arff files
- Use Weka explorer to try out the best classification algorithims
- Programatically use weka to train classifier and predict a new instance
- Write a program to tie it all together
It’s funny how a simple thing like asking whether something is a statement or question gets you knee deep in Natural Language Processing and Machine Learning pretty fast.
We’ve learned a lot, now let’s have a bit of fun. Now that we can classify speech acts, we can make a sort of proto chat bot with a really limited responses.
Proto Chat Bot
Here we are going to be a bit loose and actually check if a question mark is used. If it is, we will automatically mark it as a question. Otherwise, we will classify it.
(defn respond [text]
(let [question-mark? (re-find #"\?$" text)
type (if question-mark?
:question
(classify-text text))]
(case type
:question "That is an interesting question."
:statement "Nice to know."
:expressive ":)")))
We just need a quick repl and main function now:
(defn repl []
(do
(print ">> ")
(flush))
(let [input (read-line)]
(if-not (= input "quit")
(do
(println (try (c/respond input)
(catch Exception e (str "Sorry: " e " - " (.getMessage e)))))
(recur))
(do (println "Bye!")
(System/exit 0)))))
(defn -main [& args]
(println "Hello. Let's chat.")
(flush)
(repl))
Testing it out with lein run, we can have a little chat:
Hello. Let's chat.
>> Hi
:)
>> Do you know where I can go to buy cheese
That is an interesting question.
>> I am a big cheese fan
Nice to know.
>> you are quite smart
Nice to know.
>> bye
:)
Want more? Check out the code https://github.com/gigasquid/speech-acts-classifier.
Special thanks to Paul deGrandis for allowing me to pick his awesome brain on AI things