Simple Autoencoder

If you look long enough into the autoencoder, it looks back at you.
The Autoencoder is a fun deep learning model to look into. Its goal is simple: given an input image, we would like to have the same output image.
It’s sort of an identity function for deep learning models, but it is composed of two parts: an encoder and decoder, with the encoder translating the images to a latent space representation and the encoder translating that back to a regular images that we can view.
We are going to make a simple autoencoder with Clojure MXNet for handwritten digits using the MNIST dataset.
The Dataset
We first load up the training data into an iterator that will allow us to cycle through all the images.
1 2 3 4 5 6 | |
Notice there the the input shape is 784. We are purposely flattening out our 28x28 image of a number to just be a one dimensional flat array. The reason is so that we can use a simpler model for the autoencoder.
We also load up the corresponding test data.
1 2 3 4 5 6 | |
When we are working with deep learning models we keep the training and the test data separate. When we train the model, we won’t use the test data. That way we can evaluate it later on the unseen test data.
The Model
Now we need to define the layers of the model. We know we are going to have an input and an output. The input will be the array that represents the image of the digit and the output will also be an array which is reconstruction of that image.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
From the model above we can see the input (image) being passed through simple layers of encoder to its latent representation, and then boosted back up from the decoder back into an output (image). It goes through the pleasingly symmetric transformation of:
784 (image) -> 100 -> 50 -> 50 -> 100 -> 784 (output)
We can now construct the full model with the module api from clojure-mxnet.
1 2 3 4 5 6 7 | |
Notice that when we are binding the data-shapes and label-shapes we are using only the data from our handwritten digit dataset, (the images), and not the labels. This will ensure that as it trains it will seek to recreate the input image for the output image.
Before Training
Before we start our training, let’s get a baseline of what the original images look like and what the output of the untrained model is.
To look at the original images we can take the first training batch of 100 images and visualize them. Since we are initially using the flattened [784] image representation. We need to reshape it to the 28x28 image that we can recognize.
1 2 3 4 | |

We can also do the same visualization with the test batch of data images by putting them into the predict-batch and using our model.
1 2 3 4 5 | |

They are not anything close to recognizable as numbers.
Training
The next step is to train the model on the data. We set up a training function to step through all the batches of data.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
For each batch of 100 images it is doing the following:
- Run the forward pass of the model with both the data and label being the image
- Update the accuracy of the model with the
mse(mean squared error metric) - Do the backward computation
- Update the model according to the optimizer and the forward/backward computation.
Let’s train it for 3 epochs.
1 2 3 4 5 6 | |
After training
We can check the test images again and see if they look better.
1 2 3 4 5 | |

Much improved! They definitely look like numbers.
Wrap up
We’ve made a simple autoencoder that can take images of digits and compress them down to a latent space representation the can later be decoded into the same image.
If you want to check out the full code for this example, you can find it here.
Stay tuned. We’ll take this example and build on it in future posts.
Clojure MXNet April Update
Spring is bringing some beautiful new things to the Clojure MXNet. Here are some highlights for the month of April.
Shipped
We’ve merged 10 PRs over the last month. Many of them focus on core improvements to documentation and usability which is very important.
The MXNet project is also preparing a new release 1.4.1, so keep on the lookout for that to hit in the near future.
Clojure MXNet Made Simple Article Series
Arthur Caillau added another post to his fantastic series - MXNet made simple: Pretrained Models for image classification - Inception and VGG
Cool Stuff in Development
New APIs
Great progress was made on the new version of the API for the Clojure NDArray and Symbol APIs by Kedar Bellare. We now have an experimental new version of the apis that are generated more directly from the C code so that we can have more control over the output.
For example the new version of the generated api for NDArray looks like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
as opposed to:
1 2 3 4 5 6 7 8 | |
So much nicer!!!
BERT (State of the Art for NLP)
We also have some really exciting examples for BERT in a PR that will be merged soon. If you are not familiar with BERT, this blog post is a good overview. Basically, it’s the state of the art in NLP right now. With the help of exported models from GluonNLP, we can do both inference and fine tuning of BERT models in MXNet with Clojure! This is an excellent example of cross fertilization across the GluonNLP, Scala, and Clojure MXNet projects.
There are two examples.
1) BERT question and answer inference based off of a fine tuned model of the SQuAD Dataset in GluonNLP which is then exported. It allows one to actually do some natural language question and answering like:
1 2 3 4 5 6 7 | |
2) The second example is using the exported BERT base model and then fine tuning it in Clojure to do a task with sentence pair classification to see if two sentences are equivalent or not.
The nice thing about this is that we were able to convert the existing tutorial in GluonNLP over to a Clojure Jupyter notebook with the lein-jupyter plugin. I didn’t realize that there is a nifty save-as command in Jupyter that can generate a markdown file, which makes for very handy documentation. Take a peek at the tutorial here. It might make its way into a blog post on its own in the next week or two.
Upcoming Events
I’ll be speaking about Clojure MXNet at the next Scicloj Event on May 15th at 10PM UTC. Please join us and get involved in making Clojure a great place for Data Science.
I’m also really excited to attend ICLR in a couple weeks. It is a huge conference that I’m sure will melt my mind with the latest research in Deep Learning. If anyone else is planning to attend, please say hi :)
Get Involved
As always, we welcome involvement in the true Apache tradition. If you have questions or want to say hi, head on over the the closest #mxnet room on your preferred server. We are on Clojurian’s slack and Zulip
Cat Picture of the Month
To close out, let’s take a lesson from my cats and don’t forget the importance of naps.

Have a great rest of April!
Clojure MXNet March Update
I’m starting a monthly update for Clojure MXNet. The goal is to share the progress and exciting things that are happening in the project and our community.
Here’s some highlights for the month of March.
Shipped
Under the shipped heading, the 1.4.0 release of MXNet has been released, along with the Clojure MXNet Jars. There have been improvements to the JVM memory management and an Image API addition. You can see the full list of changes here
Clojure MXNet Made Simple Article Series
Arthur Caillau authored a really nice series of blog posts to help get people started with Clojure MXNet.
- Getting started with Clojure and MXNet on AWS
- MXNet made simple: Clojure NDArray API
- MXNet made simple: Clojure Symbol API
- MXNet made simple: Clojure Module API
- MXNet made simple: Clojure Symbol Visualization API
- MXNet made simple: Image Manipulation with OpenCV and MXNet
Lein Template & Docker file
Nicolas Modrzyk created a Leiningen template that allows you to easily get a MXNet project started - with a notebook too! It’s a great way to take Clojure MXNet for a spin
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
There also is a docker file as well
1 2 3 4 5 6 7 8 | |
Cool Stuff in Development
There are a few really interesting things cooking for the future.
One is a PR for memory fixes from the Scala team that is getting really close to merging. This will be a solution to some the the memory problems that were encountered by early adopters of the Module API.
Another, is the new version of the API for the Clojure NDArray and Symbol APIs that is being spearheaded by Kedar Bellare
Finally, work is being started to create a Gluon API for the Clojure package which is quite exciting.
Get Involved
As always, we welcome involvement in the true Apache tradition. If you have questions or want to say hi, head on over the the closest #mxnet room on your preferred server. We are on Clojurian’s slack and Zulip.
Cat Picture of the Month
There is no better way to close out an update than a cat picture, so here is a picture of my family cat watching birds at the window.

Have a great rest of March!
Object Detection With Clojure MXNet

Object detection just landed in MXNet thanks to the work of contributors Kedar Bellare and Nicolas Modrzyk. Kedar ported over the infer package to Clojure, making inference and prediction much easier for users and Nicolas integrated in his Origami OpenCV library into the the examples to make the visualizations happen.
We’ll walk through the main steps to use the infer object detection which include creating the detector with a model and then loading the image and running the inference on it.
Creating the Detector
To create the detector you need to define a couple of things:
- How big is your image?
- What model are you going to be using for object detection?
In the code below, we are going to be giving it an color image of size 512 x 512.
1 2 3 4 5 6 7 | |
- The shape is going to be
[1 3 512 512].- The
1is for the batch size which in our case is a single image. - The
3is for the channels in the image which for a RGB image is3 - The
512is for the image height and width.
- The
- The
layoutspecifies that the shape given is in terms ofNCHWwhich is batch size, channel size, height, and width. - The
dtypeis the image data type which will be the standardFLOAT32 - The
model-path-prefixpoints to the place where the trained model we are using for object detection lives.
The model we are going to use is the Single Shot Multiple Box Object Detector (SSD). You can download the model yourself using this script.
How to Load an Image and Run the Detector
Now that we have a model and a detector, we can load an image up and run the object detection.
To load the image use load-image which will load the image from the path.
1
| |
Then run the detection using infer/detect-objects which will give you the top five predictions by default.
1
| |
It will give an output something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
which you can then use to draw bounding boxes on the image.
Try Running the Example

One of the best ways to explore using it is with the object detection example in the MXNet repo. It will be coming out officially in the 1.5.0 release, but you can get an early peek at it by building the project and running the example with the nightly snapshot.
You can do this by cloning the MXNet Repo and changing directory to contrib/clojure-package.
Next, edit the project.clj to look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
If you are running on linux, you should change the mxnet-full_2.11-osx-x86_64-cpu to mxnet-full_2.11-linux-x86_64-cpu.
Next, go ahead and do lein test to make sure that everything builds ok. If you run into any trouble please refer to README for any missing dependencies.
After that do a lein install to install the clojure-mxnet jar to your local maven. Now you are ready to cd examples/infer/object-detection to try it out. Refer to the README for more details.
If you run into any problems getting started, feel free to reach out in the Clojurian #mxnet slack room or open an issue at the MXNet project. We are a friendly group and happy to help out.
Thanks again to the community for the contributions to make this possible. It’s great seeing new things coming to life.
Happy Object Detecting!
How to GAN a Flan
It’s holiday time and that means parties and getting together with friends. Bringing a baked good or dessert to a gathering is a time honored tradition. But what if this year, you could take it to the next level? Everyone brings actual food. But with the help of Deep Learning, you can bring something completely different - you can bring the image of baked good! I’m not talking about just any old image that someone captured with a camera or created with a pen and paper. I’m talking about the computer itself creating. This image would be never before seen, totally unique, and crafted by the creative process of the machine.
That is exactly what we are going to do. We are going to create a flan

If you’ve never had a flan before, it’s a yummy dessert made of a baked custard with caramel sauce on it.
“Why a flan?”, you may ask. There are quite a few reasons:
- It’s tasty in real life.
- Flan rhymes with GAN, (unless you pronounce it “Gaaahn”).
- Why not?
Onto the recipe. How are we actually going to make this work? We need some ingredients:
- Clojure - the most advanced programming language to create generative desserts.
- Apache MXNet - a flexible and efficient deep learning library that has a Clojure package.
- 1000-5000 pictures of flans - for Deep Learning you need data!
Gather Flan Pictures
The first thing you want to do is gather your 1000 or more images with a scraper. The scraper will crawl google, bing, or instagram and download pictures of mostly flans to your computer. You may have to eyeball and remove any clearly wrong ones from your stash.
Next, you need to gather all these images in a directory and run a tool called im2rec.py on them to turn them into an image record iterator for use with MXNet. This will produce an optimized format that will allow our deep learning program to efficiently cycle through them.
Run:
python3 im2rec.py --resize 28 root flan
to produce a flan.rec file with images resized to 28x28 that we can use next.
Load Flan Pictures into MXNet
The next step is to import the image record iterator into the MXNet with the Clojure API. We can do this with the io namespace.
Add this to your require:
[org.apache.clojure-mxnet.io :as mx-io]
Now, we can load our images:
1 2 3 | |
Now, that we have the images, we need to create our model. This is what is actually going to do the learning and creating of images.
Creating a GAN model.
GAN stands for Generative Adversarial Network. This is a incredibly cool deep learning technique that has two different models pitted against each, yet both learning and getting better at the same time. The two models are a generator and a discriminator. The generator model creates a new image from a random noise vector. The discriminator then tries to tell whether the image is a real image or a fake image. We need to create both of these models for our network.
First, the discriminator model. We are going to use the symbol namespace for the clojure package:
1 2 3 4 5 6 7 8 9 10 11 12 | |
There is a variable for the data coming in, (which is the picture of the flan), it then flows through the other layers which consist of convolutions, normalization, and activation layers. The last three layers actually repeat another two times before ending in the output, which tells whether it thinks the image was a fake or not.
The generator model looks similar:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
There is a variable for the data coming in, but this time it is a random noise vector. Another interesting point that is is using a deconvolution layer instead of a convolution layer. The generator is basically the inverse of the discriminator. It starts with a random noise vector, but that is translated up through the layers until it is expanded to a image output.
Next, we iterate through all of our training images in our flan-iter with reduce-batches. Here is just an excerpt where we get a random noise vector and have the generator run the data through and produce the output image:
1 2 3 4 5 6 7 8 | |
The whole code is here for reference, but let’s skip forward and run it and see what happens.

FLANS!! Well, they could be flans if you squint a bit.
Now that we have them kinda working for a small image size 28x28, let’s biggerize it.
Turn on the Oven and Bake
Turning up the size to 128x128 requires some alterations in the layers’ parameters to make sure that it processes and generates the correct size, but other than that we are good to go.
Here comes the fun part, watching it train and learn:
Epoch 0

In the beginning there was nothing but random noise.
Epoch 10

It’s beginning to learn colors! Red, yellow, brown seem to be important to flans.
Epoch 23
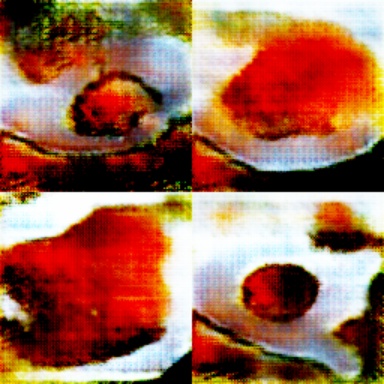
It’s learning shapes! It has learned that flans seem to be blob shaped.
Epoch 33
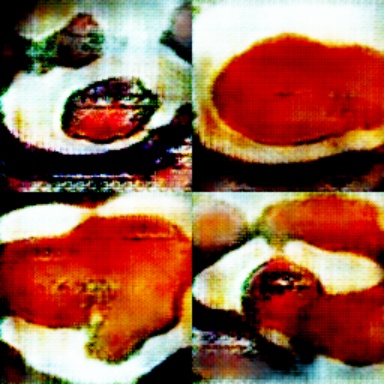
It is moving into its surreal phase. Salvidor Dali would be proud of these flans.
Epoch 45
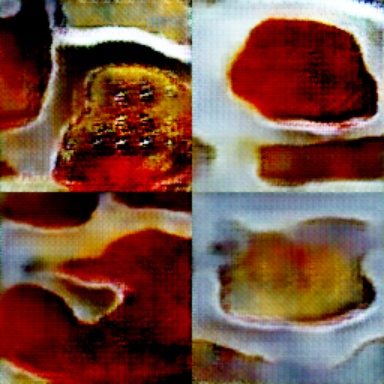
Things take a weird turn. Does that flan have eyes?
Epoch 68
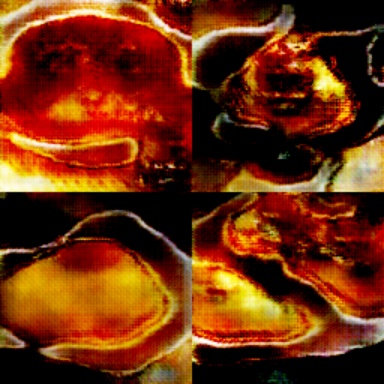
Even worse. Are those demonic flans? Should we even continue down this path?
Answer: Yes - the training must go on..
Epoch 161
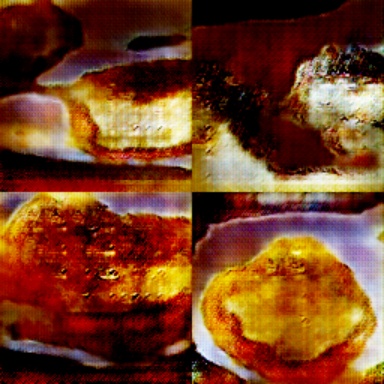
Big moment here. It looks like something that could possibly be edible.
Epoch 170
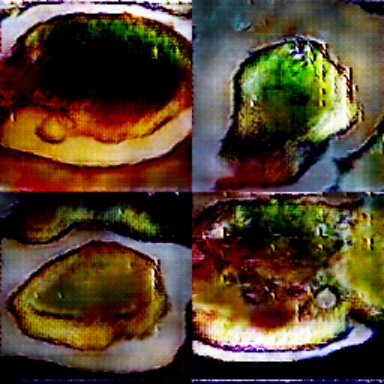
Ick! Green Flans! No one is going to want that.
Epoch 195

We’ve achieved maximum flan, (for the time being).
Explore
If you are interested in playing around with the pretrained model, you can check it out here with the pretrained function. It will load up the trained model and generate flans for you to explore and bring to your dinner parties.
Wrapping up, training GANs is a lot of fun. With MXNet, you can bring the fun with you to Clojure.
Want more, check out this Clojure Conj video - Can You GAN?.
Clojure MXNet - the Module API

This is an introduction to the high level Clojure API for deep learning library MXNet.
The module API provides an intermediate and high-level interface for performing computation with neural networks in MXNet.
To follow along with this documentation, you can use this namespace to with the needed requires:
1 2 3 4 5 6 7 8 | |
Prepare the Data
In this example, we are going to use the MNIST data set. If you have cloned the MXNet repo and cd contrib/clojure-package, we can run some helper scripts to download the data for us.
1 2 3 4 | |
MXNet provides function in the io namespace to load the MNIST datasets into training and test data iterators that we can use with our module.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Preparing a Module for Computation
To construct a module, we need to have a symbol as input. This symbol takes input data in the first layer and then has subsequent layers of fully connected and relu activation layers, ending up in a softmax layer for output.
1 2 3 4 5 6 7 8 9 | |
You can also write this with the as-> threading macro.
1 2 3 4 5 6 7 8 | |
By default, context is the CPU. If you need data parallelization, you can specify a GPU context or an array of GPU contexts like this (m/module out {:contexts [(context/gpu)]})
Before you can compute with a module, you need to call bind to allocate the device memory and init-params or set-params to initialize the parameters. If you simply want to fit a module, you don’t need to call bind and init-params explicitly, because the fit function automatically calls them if they are needed.
1 2 3 4 5 | |
Now you can compute with the module using functions like forward, backward, etc.
Training and Predicting
Modules provide high-level APIs for training, predicting, and evaluating. To fit a module, call the fit function with some data iterators:
1 2 3 4 | |
You can pass in batch-end callbacks using batch-end-callback and epoch-end callbacks using epoch-end-callback in the fit-params. You can also set parameters using functions like in the fit-params like optimizer and eval-metric. To learn more about the fit-params, see the fit-param function options. To predict with a module, call predict with a DataIter:
1 2 3 4 | |
The module collects and returns all of the prediction results. For more details about the format of the return values, see the documentation for the predict function.
When prediction results might be too large to fit in memory, use the predict-every-batch API.
1 2 3 4 5 6 7 | |
If you need to evaluate on a test set and don’t need the prediction output, call the score function with a data iterator and an eval metric:
1
| |
This runs predictions on each batch in the provided data iterator and computes the evaluation score using the provided eval metric. The evaluation results are stored in metric so that you can query later.
Saving and Loading
To save the module parameters in each training epoch, use a checkpoint function:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
To load the saved module parameters, call the load-checkpoint function:
1 2 3 | |
To initialize parameters, Bind the symbols to construct executors first with bind function. Then, initialize the parameters and auxiliary states by calling init-params function.
1 2 3 | |
To get current parameters, use params
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
To assign parameter and aux state values, use set-params function.
1 2 | |
To resume training from a saved checkpoint, instead of calling set-params, directly call fit, passing the loaded parameters, so that fit knows to start from those parameters instead of initializing randomly
Create fit-params, and then use it to set begin-epoch so that fit knows to resume from a saved epoch.
1 2 3 4 5 6 | |
If you are interested in checking out MXNet and exploring on your own, check out the main page here with instructions on how to install and other information.
See other blog posts about MXNet
Clojure MXNet Joins the Apache MXNet Project
I’m delighted to share the news that the Clojure package for MXNet has now joined the main Apache MXNet project. A big thank you to the efforts of everyone involved to make this possible. Having it as part of the main project is a great place for growth and collaboration that will benefit both MXNet and the Clojure community.
Invitation to Join and Contribute
The Clojure package has been brought in as a contrib clojure-package. It is still very new and will go through a period of feedback, stabilization, and improvement before it graduates out of contrib.
We welcome contributors and people getting involved to make it better.
Are you interested in Deep Learning and Clojure? Great - Join us!
There are a few ways to get involved.
- Check out the current state of the Clojure package some contribution needs here https://cwiki.apache.org/confluence/display/MXNET/Clojure+Package+Contribution+Needs
- Join the Clojurian Slack #mxnet channel
- Join the MXNet dev mailing list by sending an email to
dev-subscribe@mxnet.apache.org.. - Join the MXNET Slack channel - You have to join the MXnet dev mailing list first, but after that says you would like to join the slack and someone will add you.
- Join the MXNet Discussion Forum
Want to Learn More?
There are lots of examples in the package to check out, but a good place to start are the tutorials here https://github.com/apache/incubator-mxnet/tree/master/contrib/clojure-package/examples/tutorial
There is a blog walkthough here as well - Clojure MXNet Module API
Meet Clojure MXNet - NDArray
This is the beginning of a series of blog posts to get to know the Apache MXNet Deep Learning project and the new Clojure language binding clojure-package
MXNet is a first class, modern deep learning library that AWS has officially picked as its chosen library. It supports multiple languages on a first class basis and is incubating as an Apache project.
The motivation for creating a Clojure package is to be able to open the deep learning library to the Clojure ecosystem and build bridges for future development and innovation for the community. It provides all the needed tools including low level and high level apis, dynamic graphs, and things like GAN and natural language support.
So let’s get on with our introduction with one of the basic building blocks of MXNet, the NDArray.
Meet NDArray
The NDArray is the tensor data structure in MXNet. Let’s start of by creating one. First we need to require the ndarray namespace:
1 2 | |
Now let’s create an all zero array of dimension 100 x 50
1 2 | |
We can check the shape of this by using shape-vec
1 2 | |
There is also a quick way to create an ndarray of ones with the ones function:
1
| |
Ones and zeros are nice, but what an array with specific contents? There is an array function for that. Specific the contents of the array first and the shape second:
1 2 | |
To convert it back to a vector format, we can use the ->vec function.
1 2 | |
Now that we know how to create NDArrays, we can get to do something interesting like operations on them.
Operations
There are all the standard arithmetic operations:
1 2 3 4 | |
Note that the original ndarrays are unchanged.
1 2 | |
But, we can change that if we use the inplace operators:
1 2 | |
There are many more operations, but just to give you a taste, we’ll take a look a the dot product operation:
1 2 3 4 5 | |
If you are curious about the other operators available in NDArray API check out the MXNet project documentation page
Now that we have ndarrays and can do calculations on them, we might want to save and load them.
Saving and Loading
You can save ndarrays with a name as a map like:
1
| |
To load them, you just specify the filename and the map is returned.
1 2 3 | |
One more cool thing, we can even due our operations on the cpu or gpu.
Multi-Device Support
When creating an ndarray you can use a context argument to specify the device. To do this, we will need the help of the context namespace.
1
| |
By default, the ndarray is created on the cpu context.
1 2 3 | |
But we can specify the gpu instead, (if we have a gpu enabled build).
1
| |
Note: Operations among different contexts are currently not allowed, but there is a copy-to function that can help copy the content from one device to another and then continue on with the computation.
Wrap up
I hope you’ve enjoyed the brief introduction to the MXNet library, there is much more to explore in future posts. If you are interested in giving it a try, there are native jars for OSX cpu and Linux cpu/gpu available and the code for the ndarray tutorial can be found here
Please remember that the library is in a experimential state, so if you encounter any problems or have any other feedback, please log an issue so bugs and rough edges can be fixed :).
On Staying Technical
I was 10 years into my career when I met her. I could count the number of other women programmers I had worked with on one hand and none of them had young children at home like me. She was not only incredibly experienced and competent, but also had a son in college. I was curious about her career path so I asked her one day at lunch why she was still programming and hadn’t become a manager instead.
She smiled at me kindly and replied, “I’ve worked very hard to stay exactly where I am”, and I was enlightened.
Cats and Dogs With Cortex Redux
I wrote a blog post a while back about using a Clojure machine learning library called Cortex to do the Kaggle Cats and Dogs classification challenge.
I wanted to revisit it for a few reasons. The first one is that the Cortex library has progressed and improved considerably over the last year. It’s still not at version 1.0, but it my eyes, it’s really starting to shine. The second reason is that they recently published an example of using the RESNET50 model, (I’ll explain later on), to do fine-tuning or transfer learning. The third reason, is that there is a great new plugin for leiningen the supports using Jupyter notebooks with Clojure projects. These notebooks are a great way of doing walkthroughs and tutorials.
Putting all these things together, I felt like I was finally at a stage where I could somewhat replicate the first lesson in the Practical Deep Learning Course for Coders with Cats and Dogs - although this time all in Clojure!
Where to Start?

In the last blog post, we created our deep learning network and trained the data on scaled down images (like 50x50) from scratch. This time we are much smarter.
We are still of course going to have to get a hold of all the training data from Kaggle Cats vs Dogs Challenge. The big difference is this time, we are just going to have to train our model for 1 epoch. What’s more, the results will be way better than before.
How is this possible? We are going to use an already trained model, RESNET50. This model has already been painstakingly trained with a gigantic network that is 50 layers deep on the ImageNet challenge. That’s a challenge that has models try to classify a 1000 different categories. The theory is that the inner layers of the network have already learned about the features that make up cats and dogs, all we would need to do is peel off the final layer of the network and graft on a new layers that just learns the final classification for our 2 categories of cats and dogs. This is called transfer learning or retraining.
Plan of Action
- Get all the cats and dogs pictures in the right directory format for training
- Train the model with all but the last layer in the RESNET model. The last layer we are going to replace with our own layer that will finetune it to classify only cats and dogs
- Run the test data and come up with a spreadsheet of results to submit to Kaggle.
Getting all the data pictures in the right format
This is the generally the most time consuming step of most deep learning. I’ll spare you the gritty details but we want to get all the pictures from the train.zip into the format
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
The image sizes must also all be resized to match the input of the RESNET50. That means they all have to be 224x224.
Train the model
The cortex functions allow you to load the resnet50 model, remove the last layer, freeze all the other layers so that they will not be retrained, and add new layers.
I was surprised that I could actually train the model with all the images at 224x244 with the huge RESNET50 model. I built the uberjar and ran it which helped the performance.
lein uberjar
java -jar target/cats-dogs-cortex-redux.jar
Training one epoch took me approximately 6 minutes. Not bad, especially considering that’s all the training I really needed to do.
1 2 | |
The key point is that it saved the fine tuned network to trained-network.nippy
Run the Kaggle test results and submit the results
You will need to do a bit more setup for this. First, you need to get the Kaggle test images for classification. There are 12500 of these in the test.zip file from the site. Under the data directory, create a new directory called kaggle-test. Now unzip the contents of test.zip inside that folder. The full directory with all the test images should now be:
data/kaggle-test/test
This step takes a long time and you might have to tweak the batch size again depending on your memory. There are 12500 predications to be made. The main logic for this is in function called (kaggle-results batch-size). It will take a long time to run. It will print the results as it goes along to the kaggle-results.csv file. If you want to check progress you can do wc -l kaggle-results.csv
For me locally, with (cats-dogs/kaggle-results 100) it took me 28 minutes locally.
Compare the results
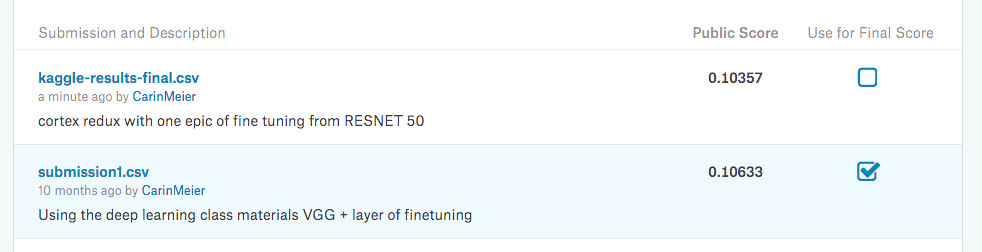
My one epoch of fine tuning beat my best results of going through the Practical Deep Learning exercise with the fine tuning the VGG16 model. Not bad at all.
Summary
For those of you that are interested in checking out the code, it’s out there on github
Even more exciting, there is a walkthrough in a jupyter notebook with a lein-jupyter plugin.
The Deep Learning world in Clojure is an exciting place to be and gaining tools and traction more and more.