Embedded Interop Between Clojure, R, and Python With GraalVM

In my talk at Clojure Conj I mentioned how a project from Oracle Labs named GraalVM might have to potential for Clojure to interop with Python on the same VM. At the time of the talk, I had just learned about it so I didn’t have time to take a look at it. Over the last week, I’ve managed to take it for a test drive and I wanted to share what I found.
Are you ready?
In this example, we will be using an ordinary Leinengen project and using the REPL we will interop with both R and python.
But first will need a bit of setup.
We will download the Graal project so we can use its java instead of our own.
Once we have it downloaded we will configure our PATH to use Graal’s java instead of our own.
1
| |
Now, we can create a new lein project and run lein repl and begin the fun.
The Polyglot Context
In our new namespace, we just need to import the Polyglot Context to get started:
1 2 3 4 5 | |
Now, we are ready to actually try to run some R and Python code right in our REPL. Let’s start first with R.
Interoping with R
The main function we are going to use is the eval function in the context. Let’s start small with some basic math.
1 2 3 4 | |
Wow! It actually did something. It returned something called a Polyglot Value with what looks like the right answer in it.
Emboldened by our early success, let’s try something a little more complicated like calling a function.
1 2 3 4 5 6 7 | |
Again, it looks like it worked. Let’s try to get the result back into Clojure as a value we can work with. We could ask the result what sort of type it is with
1
| |
but let’s just use clojure.edn to read the string and save some time.
1 2 3 4 5 6 | |
It would be nice to have a easier way to export symbols and import symbols to and from the guest and host language. In fact, Graal provides a way to do this but to do this in Clojure, we would need something else called Truffle.
Truffle is part of the Graal project and is a framework for implementing languages with the Graal compliler. There are quite a few languages implemented with the Truffle framework. R is one of them.
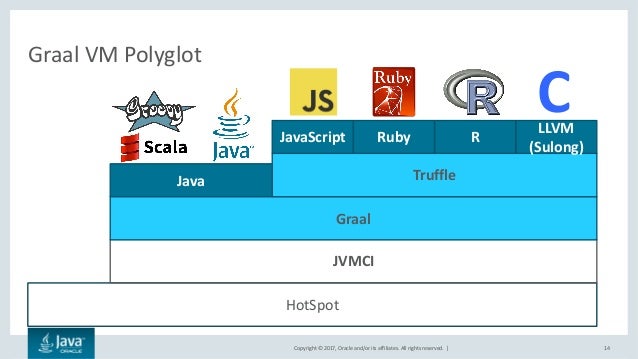
My understanding is that if Clojure was implemented as a truffle lang, then interop could be much more seamless like this example in Ruby

But let’s continue in our exploration. What about doing something more interesting, like importing a useful R library and using it. How about the numDeriv package that supports Accurate Numerical Derivatives?
First we import the package using cran.
1 2 3 | |
If you are doing this at your REPL, you can will see lots of text going on in your lein repl process at this point. It’s going out and figuring out what deps you need and installing them in your /graalvm-0.28.2/jre/languages/R directory structure.
After it is done, we can actually use it!
1 2 3 4 5 6 7 8 9 | |
This has a bit more interesting result as an array. But the Context has ways of dealing with it.
1 2 3 4 5 6 7 8 9 | |
So, we’ve showed basic interop with R - which is pretty neat. What about Python?
Interoping with Python
Truffle is scheduled to fully support Python in 2018, but there is already an early alpha version in the Graal download that we can play with.
1 2 3 4 5 | |
Neat!
It is still a long way for import numpy or import tensorflow but cPython compatibility is the goal. Although the c-extensions are the really tricky part.
So keep an eye on Graal and Truffle for the future and wish the Oracle Labs team the best on their mission to make the JVM Polyglot.
Footnotes
If you are interested in playing with the code. I have a github repo here graal-test. If you are interested in watching a video, I really liked this one. There are also some really nice examples of running in polyglot mode with R and Java and JS here https://github.com/graalvm/examples.
Self Publishing for the Creative Coder
So, you have an idea for a fiction book. First, let me tell you that it’s a good idea and it’s a great thing that you are a coder. Quite a few successful authors have a background in software development. Arrival, (which is a fabulous movie), comes from the book, Stories of your Life, written by a fellow programmer Ted Chiang. Charlie Stross is another fine example. One of my favorites is Daniel Suarez, the author of the Daemon and more recently Change Agent. So yes, you can write a fiction book and you’re in good company. This post is dedicated to help make it happen.
So how do you know about self publishing?
Two years ago, I had a semi-crazy idea for a tween/teen scifi book. At the time, my daughter was into all the popular books of time like Hunger Games and Divergent. The thing that I really liked about them was the strong female protagonist. The only thing that I thought was missing was a story that focused on a girl who could code. It would make it even better if she had coding super powers. The idea for Code Shifter was born. One of the things that I wanted to explore in writing the book was to have real programming code in the book but not have it be a learning how to code book. The code would exist as part of the story and if the reader picked up concepts along the way, great. Even if they didn’t, it would lay the positive groundwork to have them be more open to it later.
Books, like software, always take longer than you plan. My daughter and I enjoyed working on it together and over time it grew into a book that we could share with others. Along the way, I learned quite a bit about writing books, publishing, and other things that I wish I had known beforehand.
What did you use to write the book?
In the book world, your story is referred to as your manuscript. As a tool to produce it, I cannot speak highly enough of Leanpub. I found it easy and productive to work in as a programmer. For example, my setup was pretty painless.
In the repo, I had a manuscript directory, in which there was a Book.txt file that listed the chapter files.
1 2 3 4 | |
Each chapter file in turn was written in markdown. For example, chapter2.txt looked like this:
1 2 3 4 5 6 | |
From there, my process looked like:
- Write a bit in my favorite editor, (Emacs of course), and make a commit.
- Push the commit to github, which is registered with the Leanpub project
- Log onto the Leanpub project and hit the preview button. This would generate a pdf and ebook that I could share with my daughter for feedback.
Advantages of Leanpub for development.
As I said earlier, I’m a fan. Using git for revisions is incredibly useful. I shudder to think of people writing in Word without version control. The ability to easily create PDF and ebook formats was also very convenient. The markdown format has excellent code support. There is also the option as publishing your work as you go. However, I think that this is more useful with a technical book than with fiction.
Disadvantages of Leanpub for development
If you are going to work with an freelance editor or share your work with someone in the mainstream book world, they are not going to want pdf. They usually want a doc version. It took me a bit of research to find a good converter, pandoc. With it, you can convert from markdown to Word with things looking pretty good. Don’t try to do pdf to Word. I found it a big recipe for fail.
Finally, the book was considered done enough to think about publishing.
There was much rejoicing.
Didn’t you want to get the book into bookstores?
Of course. That would be incredibly cool. However, that requires getting into what they call traditional publishing and it is a lot more work, time, and luck. If you go this route, you will need to budget at least six months to send out form letters to agencies to have them represent your work. Also, beware of predatory services that take advantage of unsuspecting and wide eyed authors. If you are interested in this, you’ll want to start looking for agents that are interested in your type of book. Query Tracker is a great place to start.
Traditional publishing sounds hard. What about self publishing?
Self publishing is certainly an easier more direct way to bring your book to life. For me, it was the best way forward. Luckily, Leanpub made it pretty painless.
Publishing the book with Leanpub
Actually publishing the finished copy was really easy with Leanpub. All I had to do was fill in some fields on the project page and push Publish! The book was immediately ready to share with the world. Putting out an updated edition was as easy as pushing the button again. Leanpub provides online reading as well as all the ebook versions.
That was nice, but I really wanted a print copy too.
Publishing with CreateSpace
Amazon’s CreateSpace provides and excellent platform for on-demand print copies of books. This is where Leanpub comes in handy again. There is an Export Option that provides and unbranded pdf copy of your manuscript with all the correct formatting and margins required for CreateSpace. I simply exported the file and then uploaded it up to the project.

The other thing that you will want is a nice cover. There are services through CreateSpace for cover creation that you can buy or you can upload your own file. I was lucky enough to have a talented graphic designer as sister, Kristin Allmyer, who made me an awesome cover.
One of the confusing things was picking an ISBN for the print copy. You don’t need to worry about this for ebook versions but you do for a physical copy. Your choices through CreateSpace are using a provided one for free or buying your own for $99. I chose my own so I could have flexibility of working with another publisher other than Amazon if I want. If you choose that option, you can also make up your own publisher name. Mine is Gigasquid Books.
Once you have completed all the setup, they will send you a physical copy in the mail to approve. The moment you get to hold it in your hands is really magical.

If it looks alright, you hit the approve button and voilà - it’s for sale on Amazon!
Publishing with Direct Kindle Publishing
With CreateSpace, you have the option of porting your book to a Kindle format as well. It will do most of the heavy lifting of converting the files for you and a few button clicks later you have both an Kindle and print version available for your readers.
If you need to update the text of the Kindle version, Leanpub also has an export option available to produce unbranded ebook files. Just take this and upload it to your KDP account and you are good to go.
Did you run into any problems?
Of course I did. I was totally new to self publishing and I underestimated how hard copy editing is. Some errors unfortunately made it into the first version. Luckily, I had some really nice people that helped my fix it for later versions. Many thanks to Martin Plumb, Michael Daines, Paul Henrich, and S. Le Callonnec for editing help.
This brings me to my next point. If I had to do it all over again, I would publish the book in a different order. Books are really no different than software. There are going to be bugs when you first release it in the wild. It is best to embrace this. In the future, I would publish the ebook versions first, which are much easier to update and then the print versions after that.
Did you make lots of money from the book sales?
Hahaha … that’s funny. If you are interested in making money, books are not the best way to go. The margins on Leanpub are definitely better than Amazon, but if I really was interested in making money, I would have been much better off using deep learning to make a stock market predictor or code up a startup that I could sell off.
Authors in general, are much harder pressed to make livings than software developers. We should count our blessings.
Any last words of advice?
There is a great joy from creating a story and sharing it with others. Take your book idea, nurture it, and bring it to life. Then publish it and we can celebrate together.
Deep Learning in Clojure With Cortex
Update: Cortex has moved along since I first wrote this blog post, so if you are looking to run the examples, please go and clone the Cortex repo and look for the cats and dogs code in the examples directory.
There is an awesome new Clojure-first machine learning library called Cortex that was open sourced recently. I’ve been exploring it lately and wanted to share my discoveries so far in this post. In our exploration, we are going to tackle one of the classic classification problems of the internet. How do you tell the difference between a cat and dog pic?
Where to Start?

For any machine learning problem, we’re going to need data. For this, we can use Kaggle’s data for the Cats vs Dogs Challenge. The training data consists of 25,000 images of cats and dogs. That should be more than enough to train our computer to recognize cats from doggies.
We also need some idea of how to train against the data. Luckily, the Cortex project has a very nice set of examples to help you get started. In particular there is a suite classification example using MNIST, (hand written digit), corpus. This example contains a number cutting edge features that we’ll want to use:
- Uses GPU for fast computation.
- Uses a deep, multi-layered, convolutional layered network for feature recognition.
- Has “forever” training by image augmentation.
- Saves the network configuration as it trains to an external nippy file so that it can be imported later.
- Has a really nice ClojureScript front end to visualize the training progress with a confusion matrix.
- Has a way to import the saved nippy network configuration and perform inference on it to classify a new image.
Basically, it has everything we need to hit the ground running.
Data Wrangling
To use the example’s forever training, we need to get the data in the right form. We need all the images to be the same size as well as in a directory structure that is split up into the training and test images. Furthermore, we want all the dog images to be under a “dog” directory and the cat images under the “cat” directory so that the all the indexed images under them have the correct “label”. It will look like this:
1 2 3 4 5 6 7 | |
For this task, we are going to use a couple image libraries to help us out:
1 2 | |
We can resize and rewrite the original images into the form we want. For a image size, we’re going to go with 52x52. The choice is arbitrary in that I wanted it bigger than the MNIST dataset which is 28x28 so it will be easier to see, but not so big that it kills my CPU. This is even more important since we want to use RGB colors which is 3 channels as opposed to the MNIST grey scale of 1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
As far as the split between training images and testing images, we are going the go for an simple even split between testing and training data.
Network Configuration
The Network layer configuration is the meat of the whole thing. We are going to go with the exact same network description as the MNIST example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
It uses a series of convolutional layers with max pooling for feature recognition. We’ll see if it works for color versions of cats and dogs as well as street numbers.
We’ll also keep the image augmentation the same as in the example.
1 2 3 4 5 6 7 8 9 10 11 | |
It injects one augmented image into our training data by slightly rotating it and adding noise.
Running it!
It’s time to test it out. Using lein run, we’ll launch the train-forever function:
1 2 3 4 5 6 7 8 | |
This opens a port to a localhost webpage where we can view the progress http://localhost:8091/
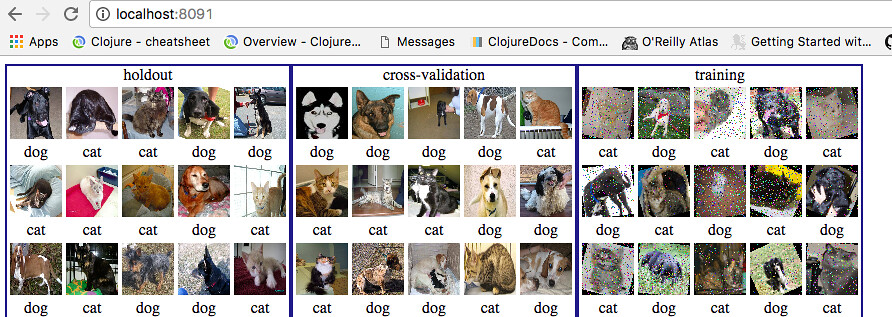
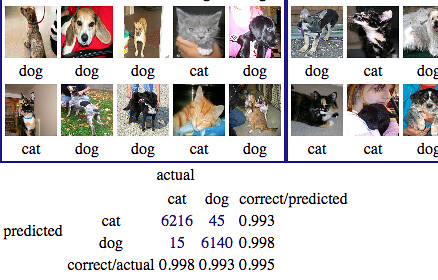
Below the confusion matrix is shown. This tracks the progress of the training in the classification. In particular, how many times it thought a cat was really a cat and how many times it got it wrong.

As we are training the data, the loss for each epoch is shown on the console as well as when it saves the network to the external file.
After only thirty minutes of training on my Mac Book Pro, we get to some pretty good results, with the correct percentage in the 99s :
It’s time to do some inference on our trained network.
Inference
Firing up a REPL we can connect to our namespace and use the label-one function from the cortex example to spot check our classification. It reads in the external nippy file that contains the trained network description, takes a random image from the testing directory, and classifies it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Running (label-one) gives us the picture:
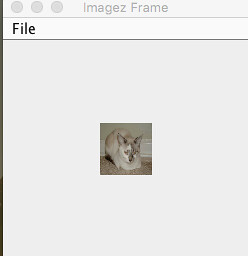
and classifies it as a cat. Yipee!
1
| |
Not bad, but let’s try it with something harder. Personally, I’m not even sure whether this is a cat or a dog.

Feeding it through the program - it says it is a cat.
1
| |
After much debate on the internet, I think that is the best answer the humans got too :)
Kaggle it
So it seems like we have a pretty good model, why don’t we submit our results to the Kaggle competition and see how it rates. All they need is to have us run the classification against their test data of 12,500 images and classify them as 1 = dog or 0 = cat in a csv format.
We will take each image and resize it, then feed it into cortex’s infer-n-observations function, to do all our classification as a batch.
1 2 3 4 5 6 7 | |
Finally, we just need to format our results to a csv file and export it:
1 2 3 4 5 6 | |
After uploading the file to the Kaggle, I was pleased that the answer got in the top 91%! It made it on the Leaderboard.
Conclusion
Using an example setup from the Cortex project and 30 minutes of processing time on my laptop, we were able to crunch through some significant data and come up with a trained classification model that was good enough to make the charts in the Kaggle competition. On top of it all, it is in pure Clojure.
In my mind, this is truely impressive and even though the Cortex library is in it’s early phases, it puts it on track to be as useful a tool as Tensor Flow for Machine Learning.
Earlier this month, I watched an ACM Learning webcast with Peter Norvig speaking on AI. In it, he spoke of one of the next challenges of AI which is to combine symbolic with neural. I can think of no better language than Clojure with it’s simplicity, power, and rich LISP heritage to take on the challenge for the future. With the Cortex library, it’s off to a great start.
If want to see all the cats vs dog Kaggle Code, it’s out on github here https://github.com/gigasquid/kaggle-cats-dogs
Genetic Programming With clojure.spec

Clojure.spec is a new library for Clojure that enables you to write specifications for your program. In an earlier post, I showed off some of it’s power to generate test data from your specifications. It’s a pretty cool feature. Given some clojure.spec code, you can generate sample data for you based off of the specifications. But what if you could write a program that would generate your clojure.spec program based off of data so that you could generate more test data?
Genetic programming
Here is where we embark for fun. We are going to use genetic programming to generate clojure.spec creatures that contain a program. Through successive generations, those creatures will breed, mutate, and evolve to fit the data that we are going to give it. Going with our creature theme, we can say that it eats a sequence of data like this
1
| |
Each creature will be represented by a map that has information about two key pieces, its program and the fitness score. Each program is going to start with a clojure.spec/cat, (which is the spec to describe a sequence). From here on out, I’m going to refer to the clojure.spec namespace as s/. So, a simple creature would look like this.
1 2 | |
How do we figure out a score from the creature’s spec? We run the spec and see how much of the data that it can successfully consume.
Scoring a creature
To score a creature, we’re going to use the clojure.spec explain-data function. It enables us to run a spec against some data and get back the problems in a data format that we can inspect. If there are no problems and the spec passes, the result is nil.
1 2 | |
However, if there is a problem, we can get information about what went wrong. In particular, we can see where it went wrong in the sequence.
1 2 | |
In the above example, the :in key tells us that it fails at index 1. This gives us all the information we need to write a score function for our creature.
1 2 3 4 5 6 7 | |
This function tries to run the spec against the data. If there are no problems, the creature gets a 100 score. Otherwise, it records the farthest point in the sequence that it got. Creatures with a higher score are considered more fit.
1 2 | |
Now that we have a fitness function to evaluate our creatures, we need a way to generate a random clojure.spec creature.

Create a random creature
This is where I really love Clojure. Code is data, so we can create the programs as lists and they are just themselves. To run the programs, we just need to call eval on them. We are going to constrain the creatures somewhat. They are all going to start out with s/cat and have a certain length of items in the sequence. Also, we are going to allow the parts of the spec to be created with certain predicates.
1
| |
Also allowing, composition with ands and ors and other sequences.
1 2 | |
We are also going to have some probability knobs to control how the random creature is constructed.
1 2 3 4 | |
The seq-prob is the probability that a new spec sub sequence will be constructed. The nest-prob is set to zero right now, to keep things simple, but if turned up with increase the chance that a nested spec sequence would occur. We are going to be writing a recursive function for generation, so we’ll keep things to a limited depth with max-depth. Finally, we have the chance that when constructing a spec sub sequence, that it will be an and/or with and-or-prob. Putting it all together with code to construct a random arg.
1 2 3 4 | |
Also creating a random sub sequence.
1 2 3 4 5 6 7 8 9 10 11 | |
Finally, we can create a random s/cat spec with
1 2 3 4 5 6 7 | |
Let’s see it in action.
1 2 | |
We can make a batch of new creatures for our initial population using this function.
1 2 3 | |
Great! Now we have a way to make new random spec creatures. But, we need a way to alter them and let them evolve. The first way to do this is with mutation.

Mutating a creature
Mutation in our case, means changing part of the code tree of the creature’s program. To keep the program runnable, we don’t want to be able to mutate every node, only specific ones. We’re going to control this by defining a mutable function that will only change nodes that start with our sequences or predicates.
1 2 3 4 | |
Then, we can use postwalk to walk the code tree and alter a node by a mutation probability factor
1 2 3 4 5 6 7 8 9 | |
Trying it on one of our creatures.
1 2 | |
We can change our creatures via mutation, but what about breeding it with other creatures?
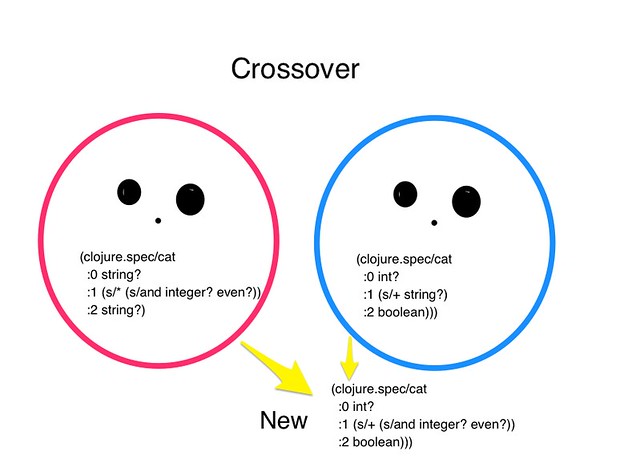
Crossovers with creatures
Crossover is another way to modify programs. It takes two creatures and swaps a node from one creature to another. To accomplish this, we’re going to use the walk function to select at a random probability the crossover node from the first node, then insert it into the second’s creatures program at another random spot.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Taking two creatures and putting them together.
1 2 3 | |
We have our ways to change our creatures to let them evolve and we have a way to rank them. What we need now is to put it together in a way that will let them evolve to the solution.
Evolving creatures
The process will be in general terms:
- Create initial population
- Rank them
- Take the top two best ones and carry them over (this is known as elitism)
- Create the next generation from by selecting creatures for crossover and mutation
- Repeat!
So how do we select the best creatures for our next population? This is an interesting question, there are many approaches. The one that we’re going to use is called tournament selection. It involves picking n creatures from the whole population and then, among those, picking the best scored one. This will allow diversity in our population that is needed for proper evolution.
1 2 3 | |
We’re now ready to write our evolve function. In it, we pass in the population size, how many generations we want, the tournament size, and of course, our test data that our creatures are going to feed on. The loop ends when it reaches a perfect fitting solution, (a creature with a score of 100), or the max generations.
Note that we have a chance for a completely random creature to appear in the generations, to further encourage diversity.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Trying it out. We get a perfect clojure.spec creature!
1 2 3 4 | |
Of course, our clojure.spec creature can generate data on its own with the exercise function. Let’s have it generate 5 more examples of data that conform to its spec.
1 2 3 4 5 6 | |
If we wanted to, we could adjust our evolve function and let it continue to evolve creatures and lots of different solutions to choose from. We could even take the generated data from the exercise function and let it generate more creatures who generate more data……
The mind boggles.
We’ll leave with a quick summary of Genetic Programming.
- Start with a way to generate random creatures
- Have a way to evaluate their fitness
- Create a way to change them for the next generations using
- Mutation
- Crossover
- Have an evolution process
- Create an initial population
- Rank them
- Create the next generation using selection techniques and mutation/ crossovers
- Don’t forget about diversity
Most importantly, have fun!
If you want to play with the code, it’s on github here https://github.com/gigasquid/genetic-programming-spec
If you want to learn more about clojure.spec this video is a great place to start. The guide is also a great reference with examples.
If you want to learn more about genetic programming, there are a couple of books I would recommend: Collective Intelligence and Genetic Algorithms + Data Structures = Evolution Programs
Hello World for the Next Generation
I sit next to my daughter, showing her programming for the first time.
1
| |
“Now press enter.”
1
| |
“Pretty cool, huh?”
She looks unimpressed. I fear I’m losing her. How can I explain that this is just a small tip of something so much bigger?
You can make the code sing to you.
You can take these numbers, turn them into notes, and line them up with the beat of your heart. Bring in the melody and chorus and build them up to a crescendo. Let it crash in waves and then
You can make the code dance for you.
You can create delicate swirls and patterns with mathematical expressions. Have them pulse to the music in a never ending prism of fractals, flexing your control with confidence because
You can make the code lift you up.
It doesn’t matter if you don’t look like them. It doesn’t matter if they think you don’t belong. They can’t hold you back. You’re smart and strong and
You can make the code create your life.
You can solve problems for people. Make things work better and faster. Keep the data flowing. Make a company for yourself. Watch that company and your power and influence in the world grow until nothing feels out of reach and then, if you’re not careful
You can make the code hard and cruel.
You can automate hate. Use the latest AI to keep them in control. Watch them with never sleeping eyes. Steal their money and point guns at them with armed robots. Then, late at night, you can think how
You can let the code control you.
You can forget the important things in life. Turn away from family and friends. Lose yourself in some self created digital representation of yourself that never feels smart enough and leaves you grasping for more. Until that day, when you walk the streets with a deadened heart and you see the sad faces all around and you remember that
You can let the code make them smile.
You can use your skills to brighten dark days. Use your programs to make them laugh. When you have their attention, inspire them to dream with you of a better world and next
You can make the code save lives.
You can turn those algorithms to heal. Dive in and join the battle against death and disease. Make sense of all the data. Then lift your head to the sky and
You can make the code reach the stars.
You can see the surface of Mars. Pick up a rock from a planet that was unimaginable generations before. Look out at what is beyond our solar system and peer into the mysteries of the beginning of time.
You can.
All these things are yours now. The terrible and beautiful power of it.
I reach down to type the code that distills my hopes and fears for the next generation.
1
| |
Then I slide the keyboard over to her, a tear sliding down my cheek, and lean over to whisper the only advice that I can form into words,
“Don’t forget the closing parens.”
Book Writing for the Busy Programmer
So you want to write a book? Awesome. I’ve been working on one too for the last year.
No, it’s not really a programming book, but it does have code in it. It’s a sci-fi/fantasy book written for my ten year daughter, but this post isn’t about that. It’s about sharing the tools and setup that I’ve found work best for me.
Tools for Writing
If the first thing you think of when you want to write a book is creating some really cool tools to help you, I can totally relate. It’s a programmer thing.
Hold on though, there’s another way.
Starting out with only my book idea, I spent some time looking at the best authoring tools out there. I knew that I wanted to able to write in an editor that I was comfortable in and in a terse format like Markdown. I also wanted to be able to use git for revision management. After searching, I settled on Leanpub
Leanpub is a free service for authoring that has Git integration in Markdown format. With it, I was able to write in my favorite text editor, (Emacs of course), commit and push my changes to my git repo, and then generate PDF and e-book formats. The multiple formats were important to me because it allowed me to share my chapters and get feedback.
Tools for Feedback
Since I was writing a book with my daughter in mind, the most important feedback was from her. After every chapter was done. I would either print her out a copy or download it to her Kindle for review. She actually really enjoyed reading it on her Kindle because it made it for more real to her. My son also got interested in the story and before long, I had them both getting in heated debates about which direction the story should go.
After my kids reviewed the chapters, I also sought some professional writing advice from a free-lance editor. I highly recommend getting this sort of feedback from an editor, writing group, or trusted friend to help you grow and improve. The one catch is that most of the writing world works with Microsoft Word, so I needed to convert my chapters to that format.
From my experience, all PDF to Word converters are full of fail. The formatting goes all over the place and your writing ends up looking like some horrible abstract text art experiment gone wrong. So far, the best converter I’ve found is pandoc. It allows you to take your Markdown files and turn them into quite presentable Word documents.
If you have a Mac, it’s as simple as brew install pandoc. Then, you can create a simple script to convert all your chapters,(or a selection) into a properly formatted Word Doc.
1 2 3 4 | |
Once you write your manuscript, (what the publishing world calls your book text), revise it, copy edit it, and walk backwards in a circle three times, you’re ready to publish.
Tools for Publishing
I don’t have any real firm advice in this area yet since I’m still in the midst of it, but I’ll share the two options that I’m looking at - traditional publishing and self publishing.
Self publishing is more easily understood of the two. You can put your book up for sale at any time through Leanpub or Amazon. For better or worse, you have complete control of the content, display, marketing, and revenue of your book.
Traditional publishing involves finding an literary agent and/or publisher to work with. This route involves pitching your manuscript to someone to represent it through a query. The advantages of this are that, (if you find a good match), you will have a team of people helping you make your book the best it can be and have the possibility of getting it on the shelf in a bookstore. One of the downsides is that the traditional publishing world takes a lot longer than pushing the self publish button.
With any luck, I’ll have a clearer picture of this all in a bit and be able to share my experiences. In the meantime, I encourage you to grab your keyboard and bring your book ideas to life.
No matter the outcome, it’s a rewarding journey.
One Fish Spec Fish

Clojure.spec is an exciting, new core library for Clojure. It enables pragmatic specifications for functions and brings a new level of robustness to building software in Clojure, along with unexpected side benefits. One of which is the ability to write specifications that generate Dr. Seuss inspired rhymes.
In this blog post, we’ll take a tour of writing specifications for a clojure function, as well as the power of data generation. First, some inspirational words:
1 2 3 4 | |
The mere shape of these words brings a function to mind. One that would take in a vector:
1
| |
and give us back a string of transformed items with the word fish added, of course.
But, let us turn our attention the parameters of this function and see how we can further specify them. Before we get started, make sure you use the latest version of clojure, currently [org.clojure/clojure "1.9.0-alpha13"], test.check [org.clojure/test.check "0.9.0"], and add clojure.spec to your namespace.
1 2 | |
Specifying the values of the parameters
Back to the parameters. The first two are integers, that’s pretty easy, but we want to say more about them. For example, we don’t want them to be very big. Having a child’s poem with the One Hundred Thousand and Thirty Three fish really won’t do. In fact, what we really want is to say is there is finite notion of fish-numbers and it’s a map of integer to string representation.
1 2 3 | |
Then, we can use the s/def to register the spec we are going to define for global reuse. We’ll use a namespaced keyword ::fish-number to express that our specification for a valid number is the keys of the fish-numbers map.
1
| |
Now that we have the specification, we can ask it if it’s valid for a given value.
1 2 | |
So 5 is not a valid number for us. We can ask it to explain why not.
1 2 | |
Which, of course, totally makes sense because 5 is not in our fish-numbers map. Now that we’ve covered the numbers, let’s look at the colors. We’ll use a finite set of colors for our specification. In addition to the classic red and blue, we’ll also add the color dun.
1
| |
You may be asking yourself, “Is dun really a color?”. The author can assure you that it is in fact a real color, like a dun colored horse. Furthermore, the word has the very important characteristic of rhyming with number one, which the author spent way too much time trying to think of.
Specifying the sequences of the values
We’re at the point where we can start specifying things about the sequence of values in the parameter vector. We’ll have two numbers followed by two colors. Using the s/cat, which is a concatentation of predicates/patterns, we can specify it as the ::first-line
1
| |
What the spec is doing here is associating each part with a tag, to identify what was matched or not, and its predicate/pattern. So, if we try to explain a failing spec, it will tell us where it went wrong.
1 2 3 | |
That’s great, but there’s more we can express about the sequence of values. For example, the second number should be one bigger than the first number. The input to the function is going to be the map of the destructured tag keys from the ::first-line
1 2 | |
Also, the colors should not be the same value. We can add these additional specifications with s/and.
1 2 3 | |
We can test if our data is valid.
1
| |
If we want to get the destructured, conformed values, we can use s/conform. It will return the tags along with the values.
1 2 | |
Failing values for the specification can be easily identified.
1 2 3 4 | |
With our specifications for both the values and the sequences of values in hand, we can now use the power of data generation to actually create data.
Generating test data - and poetry with specification
The s/exercise function will generate data for your specifications. It does 10 items by default, but we can tell it to do only 5. Let’s see what it comes up with.
1 2 3 4 5 6 | |
Hmmm… something’s not quite right. Looking at the first result [0 1 "Dun" Red"], it would result in:
1 2 3 4 | |
Although, it meets our criteria, it’s missing one essential ingredient - rhyming!
Let’s fix this by adding an extra predicate number-rhymes-with-color?.
1 2 3 4 | |
We’ll add this to our definition of ::first-line, stating that the second number parameter should rhyme with the second color parameter.
1 2 3 4 5 6 7 8 9 | |
Now, let’s try the data generation again.
1 2 3 4 5 6 7 8 9 10 11 | |
Much better. To finish things off, let’s finally create a function to create a string for our mini-poem from our data. While we’re at it, we can use our spec with s/fdef, to validate that the parameters are indeed in the form of ::first-line.
Using spec with functions
Here’s our function fish-line that takes in our values as a parameters.
1 2 3 4 5 6 7 | |
We can specify that the args for this function be validated with ::first-line and the return value is a string.
1 2 3 | |
Now, we turn on the instrumentation of the validation for functions and see what happens. To enable this, we need to add the spec.test namespace to our requires:
1 2 3 | |
The instrument function takes a fully-qualified symbol so add ` before the function name to resolve it in the context of the current namespace.
1 2 3 4 | |
But what about with bad data?
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Ah, yes - the first number must be one smaller than the second number.
Wrap up
I hope you’ve enjoyed this brief tour of clojure.spec. If you’re interested in learning more, you should check out the spec.guide. It really is an exciting, new feature to Clojure.
In the meantime, I’ll leave you with one of our generated lines, sure to be a big hit with future generations.
1 2 3 4 | |
Kolmogorov-Uspensky Machine
It happened again. I was sitting down reading a paper and I came across the phrase Kolmogorov-Uspensky machine and I had no idea what it was. My initial reaction was just to move on. It probably wasn’t important, I told myself, just a detail that I could skim over. I took a sip of my tea and continued on. The next paragraph it appeared again. It was just sticking up like a thread waiting to be pulled. Still, I resisted. After all, I wasn’t even near my computer. I would have to get up an walk into the other room. After considering it for a moment, inertia won out and I continued my reading. There it was once more. This time right in the same paragraph, silently mocking me. I knew I had to do something so I strode to my computer and pulled the thread.
What is a Kolmogorov-Uspensky machine?
The first thing I found is that the Kolmogorov-Uspensky machine, (also referred to as KUM), is very similar to the Turing machine. In fact, it shares the same computational class of being Turing-complete.

The Turing machine operates on a tape divided into cells. The head can move along the tape and read and write to it. The tape is the storage for the machine. Its movements are controlled by a collection of instructions which will be executed if certain prerequisites are met. The difference between the Turing machine and a Kolmogorov-Uspensky machine is that the KUM has a tape that can change topology. It’s a graph.
The graph of a KUM machine is not just any graph. It’s a particular kind of graph. It must have the property that if you start at a one vertex, all the other vertexes are uniquely addressable. The graph also has a active node which, in turn, has a active neighborhood of other nodes associated with it. This is not unlike the Turing machine’s head that points to the current cell. To figure out what do, the KUM machine looks at the graph to decide on what instruction to execute. The instructions can consist of adding a node or edge to the active neighborhood, removing a node or edge from the active neighborhood, or halting.
After spending some time reading and researching, I felt like a had some idea of what a Kolmogorov-Uspensky machine was but it was still a bit fuzzy. I wanted to really dig in and experience it by trying to implement one. I found an esoteric programming language called Eodermdrome that fit the bill and set to work building it out in Clojure.
Eodermdrome
An Eodermdrome program creates graphs from a string of letters. For example the graph of abcdae would produce

The program itself consists of series of commands or rules. The command will be executed if the following prereqs are met:
- The match graph in the command is a subgraph of the system graph.
- If an input set is part of the command, the input character read of the system input must match it.
A command is of the form:
- match-graph graph-replacement
- This will execute if the match-graph is a subgraph and then transform the match to the replacement.
- Example:
a abc
- (input-set) match-graph graph-replacement.
- This will execute if the match is a subgraph and if the next character of the system input matches. On executing, it will read one char from the input and then transform the match graph with the replacement.
- Example:
(1) a abc
- match-graph (output) graph-replacement.
- This will execute if the match-graph is a subgraph. On executing, it will print the output to the system and transform the match with the replacement.
- Example:
a (1) abc
- (input-set) match-graph (output) graph-replacement.
- This will execute if the match is a subgraph and if the next character of the system input matches. On executing, it will read one char from the input, print the output to the system, and then transform the match graph with the replacement.
- Example:
(0) a (1) abc
Comments are also allowed as text in between commas. In this implementation, they must be contained on a single line. Example: ,this is a comment,(1) a abc
The initial state of the graph with a program is the denoted by the graph string thequickbrownfoxjumpsoverthelazydog.
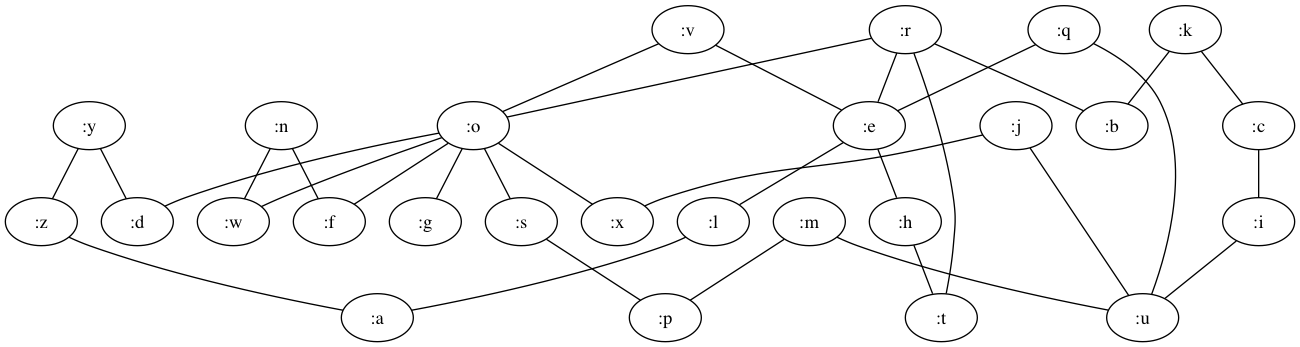
We now have all we need to walk through an example program in the Kolmogorov-Uspensky machine.
An add program
Let’s take program for adding two string of ones together separated by zeros.
1 2 3 4 | |
Given a system input of “101”, it will print out “11”. Let’s walk through what happens in the program.
Step 1 - The program starts with our graph in the initial state of our beloved thequickbrownfoxjumpsoverthelazydog configuration.

Step 2 - The first instruction matches ,takes input of ones separated by zeros and adds the ones, thequickbrownfoxjumpsoverthelazydog a with he active subgraph being the whole graph. It is replaced by the single graph node a.

Step 3 - The next instruction set (1) a ab a subgraph matches and takes a 1 off the input and transforms the graph to ab.

Step 4 - The instruction set (0) a a also matches (since a is a subgraph of ab) and it takes a zero off the input and transforms back the a to a so the graph is still ab.

Step 5 - The instruction set ab (1) a now matches and a one prints out and the ab graph changes to a.

Step 6 - Now, the (1) a ab instruction matches, it takes another 1 off the input (our last one) and transforms to ab
Step 7 - Finally, ab (1) a matches and it prints out a 1 and rewrites the graph to back to a
There are no more matching subgraphs without input required for instructions, so the program ends.
Parting thoughts and threads
The Kolmogorov-Uspensky machine is quite interesting. Not only is the idea of graph storage and rewriting appealing, it is also pretty powerful compared to Turing machines. In fact, Dima Grigoriev proved that Turing machines cannot simulate Kolmogorov machines in real time.
It’s been quite a fun and enriching jaunt. The next time you see an unfamiliar term or concept, I encourage you to pull the thread. You never know where it will take you. It’s a great way to enlarge your world.
If you are interested in the code and hacking for yourself, here is the repo https://github.com/gigasquid/eodermdrome.
Other good resources on KUM:
Fairy Tale Word Vectors

This post continues our exploration from the last blog post Why Hyperdimensional Socks Never Match. We are still working our way through Kanerva’s paper. This time, with the basics of hypervectors under our belts, we’re ready to explore how words can be expressed as context vectors. Once in a high dimensional form, you can compare two words to see how similar they are and even perform reasoning.
To kick off our word vector adventure, we need some words. Preferring whimsy over the Google news, our text will be taken from ten freely available fairy tale books on http://www.gutenberg.org/.
Gather ye nouns
Our goal is to assemble a frequency matrix, with all the different nouns as the rows and the columns will be the counts of if the word appears or not in the document. Our matrix will be binary with just 1s and 0s. The document will be a sentence or fragment of words. A small visualization is below.
| Noun | Doc1 | Doc2 |
|---|---|---|
| flower | 1 | 0 |
| king | 0 | 1 |
| fairy | 1 | 0 |
| gold | 1 | 1 |
The size of the matrix will be big enough to support hypervector behavior, but not so big as to make computation too annoyingly slow. It will be nouns x 10,000.
The first task is to get a set of nouns to fill out the rows. Although, there are numerous online sources for linguistic nouns, they unfortunately do not cover the same language spectrum as old fairy tale books. So we are going to collect our own. Using Stanford CoreNLP, we can collect a set of nouns using Grimm’s Book as a guide. There are about 2500 nouns there to give us a nice sample to play with. This makes our total matrix size ~ 2500 x 10,000.
Now that we have our nouns, let’s get down to business. We want to create an index to row to make a noun-idx and then create a sparse matrix for our word frequency matrix.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
The next thing we need to do is to have some functions to take a book, read it in, split it into documents and then update the frequency matrix.
Random indexing for the win
The interesting thing about the update method is that we can use random indexing. We don’t need to worry about having a column for each document. Because of the nature of hyperdimensions, we can randomly assign 10 columns for each document.
1 2 3 4 5 6 7 | |
The whole book is processed by slurping in the contents and using a regex to split it up into docs to update the matrix.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
We can now run the whole processing with:
1 2 | |
On my system, it only takes about 3 seconds.
Great! Now we have hypervectors associated with word frequencies. They are now context word vectors. What can we do with them.
How close is a king to a goat?
One of the things that we can do with them is find out a measure of how closely related the context of two words are by a measure of their cosine similarity. First, we need a handy function to turn a string word into a word vector by getting it out of our frequency matrix.
1 2 3 4 5 | |
Then we can make another nice function to compare two words and give a informational map back.
1 2 3 4 5 6 7 8 9 | |
Let’s take a look at the similarities of some words to king.
1 2 3 4 5 6 7 8 9 10 | |
As expected, the royal family is closer to the king then a guard or goat is.
One of the interesting things is that now we can do addition and subtraction with these word vectors and see how it affects the relation with other words.
Boy + Gold = King, Boy + Giant = Jack
We can take a look at how close boy and king are together by themselves.
1
| |
Now we can add some gold to the boy and that new word vector will be closer to king than boy was alone.
1 2 | |
Doing the same for boy and jack, we find that adding a giant moves the context closer.
1 2 3 4 | |
Amusingly, a frog and a princess make a prince.
1 2 | |
We can take this even farther by subtracting words and adding others. For example a similarity to the word queen can be obtained by subtracting man from king and adding woman.
1 2 3 | |
Similarly, a contextual closeness to father can be gotten from subtracting woman from mother and adding man.
1 2 | |
But wait, that’s not all. We can also do express facts with these word vectors and reason about them.
Reasoning with word vector with the database as a hyperdimensional value
The curious nature of hypervectors allows the storage of multiple entity, attributes in it and allow the retrieval of the likeness of them later by simple linear math - using only xor multiplication and addition. This gives us the database as a value in the form of a high dimensional vector.
For an example, say we want to express the fact that Hansel is a brother of Gretel. We can do this by adding the xor product of brother with hansel and the product of brother with Gretel.
1 2 3 4 5 6 | |
Also we can express that Jack is a brother of Hansel.
1 2 3 4 | |
We can add these two facts together to make a new hypervector value.
1 2 | |
Now we can actually reason about them and ask questions. Is Jack a brother of Hansel? With a high cosine similarity, we can assume the answer is likely.
1 2 3 4 5 | |
What about someone unrelated. Is Cinderella the brother of Gretel? - No
1 2 3 4 5 | |
Is Jack the brother of Gretel - Yes
1 2 3 4 5 | |
We can take this further by adding more facts and inventing a relation of our own.
Siblings in Hyperspace
Let’s invent a new word vector that is not in our nouns - siblings. We are going to create new random hypervector to represent it.
1
| |
We will define it in terms of word vectors that we already have. That is, siblings will be a the sum of brother + sister. We XOR multiply it by siblings to associate it with the hypervector.
1 2 | |
Now we can add some more facts. Gretel is a sister of Hansel.
1 2 3 4 5 6 | |
Gretel is also a sister of Jack.
1 2 3 4 5 6 | |
Collecting all of our facts into one hypervector (as a database).
1 2 3 4 5 | |
Now we can ask some for questions.
Are Hansel and Gretel siblings? - Yes
1 2 3 4 | |
Are John and Roland siblings - No
1 2 3 4 | |
Are Jack and Hansel siblings? - Yes
1 2 3 | |
It is interesting to think of that nothing is stopping us at this point from retracting facts by simply subtracting the fact encoded word vectors from our “database” value and making a new value from it.
Conclusions
In this fun, but casual exploration of word vector we have seen the potential for reasoning about language in a way that uses nothing more complicated than addition and multiplication. The ability to store dense information in hypervectors, extract it with simple methods, and flexibly collect it randomly, shows its versatility and power. Hyperdimensional vectors might hold the key to unlocking a deeper understanding of cognitive computing or perhaps even true artificial intelligence.
It is interesting to note that this technique is not limited to words. Other applications can be done the same way. For example a video recommendation using a hypervector with movie titles. Or perhaps even anomaly detection using sensor readings over a regular weekly time period.
Looking over our journey with word vectors. At the beginning it seemed that word vectors were magical. Now, after an understanding of the basics, it still seems like magic.
If you are interested in exploring further, feel free to use my github hyperdimensional-playground as a starting point.
Why Hyperdimensional Socks Never Match

The nature of computing in hyperdimensions is a strange and wonderful place. I have only started to scratch the surface by reading a paper by Kanerva. Not only is it interesting from a computer science standpoint, it’s also interesting from a cognitive science point of view. In fact, it could hold the key to better model AI and general reasoning. This blog is a casual stroll through some of the main points of Kanerva’s paper along with examples in Clojure to make it tangible. First things first, what is a hyperdimension?
What is a Hyperdimension and Where Are My Socks?
When we are talking about hyperdimensions, we are really talking about lots of dimensions. A vector has dimensions. A regular vector could have three dimensions [0 1 1], but a hyperdimensional vector has tons more, like 10,000 or 100,000. We call these big vectors hypervectors for short, which makes them sound really cool. Although the vectors could be made up of anything, we are going to use vectors made up of zeros and ones. To handle big computing with big vectors in a reasonable amount of time, we are also going to use sparse vectors. What makes them sparse is that most of the space is empty, (zeros). In fact, Clojure has a nice library to handle these sparse vectors. The core.matrix project from Mike Anderson is what we will use in our examples. Let’s go ahead and make some random hypervectors.
First we import the core.matrix libraries and set the implementation to vectorz which provides fast double precision vector math.
1 2 3 4 5 | |
Next we set the sz of our hypervectors to be 100,000. We also create a function to generate a random sparse hypervector by choosing to put ones in about 10% of the space.
1 2 3 4 5 6 7 8 | |
Now we can generate some.
1 2 3 4 5 6 | |
You can think of each of this hypervectors as random hyperdimensional sock, or hypersock, because that sounds cooler. These hypersocks, have curious properties. One of which is that they will ~never match.
Hypersocks never match
Because we are dealing with huge amount of dimensions, a mathematically peculiar probability distribution occurs. We can take a random hypervector to represent something, then take another one and they will different from each by about 100 STD. We can take another one and it too, will be 100 STD from the other ones. For practical purposes, we will run out of time before we will run of vectors that are unrelated. Because of this, any two hypersocks will never match each other.
How can we tell how similar two hypersocks are? The cosine to tell the similarity between two vectors. This is determined by the dot product. We can construct a cosine similarity function to give us a value from -1 to 1 to measure how alike they are with 1 being the same and -1 being the complete opposite.
1 2 3 | |
If we look at the similarity of a hypervector with itself, the result is ~1. With the other random hypervectors, it is ~0.
1 2 3 4 5 6 | |
There are other cool things we can do with hypervectors, like do math with them.
The Hamming Distance of Two Hypersocks
We can add hypervectors together with a sum mean vector. We add the vector of 1s and 0s together then we divide the resulting vector by the number of total vectors. Finally, to get back to our 1s and 0s, we round the result.
1 2 3 | |
The interesting thing about addition is that the result is similar to all the vectors in it. For example, if we add a and b together to make x, x = a + b, then x will be similar to a and similar to b.
1 2 3 4 | |
You can also do a very simple form of multiplication on vectors with 1s and 0s with using XOR. We can do this by add the two vectors together and then mapping mod 2 on each of the elements.
1 2 3 | |
We can actually use this xor-mul to calculate the Hamming distance, which is an important measure of error detection. The Hamming distance is simply the sum of all of the xor multiplied elements.
1 2 3 4 5 6 | |
This illustrates a point that xor multiplication randomizes the hypervector, but preserves the distance. In the following example, we xor multiply two random hypervectors by another and the hamming distance stays the same.
1 2 3 4 5 6 7 8 9 10 11 12 | |
So you can xor multiply your two hypersocks and move them to a different point in hyperspace, but they will still be the same distance apart.
Another great party trick in hyperspace, is the ability to bind and unbind hypervectors for use as map like pairs.
Using Hypervectors to Represent Maps
A map of pairs is a very important data structure. It gives the ability to bind symbols to values and then retrieve those values. We can do this with hypervectors too. Consider the following structure:
1 2 3 | |
We can now create hypervectors to represent each of these values. Then we can xor the hypervector symbol to the hypervector value and sum them up.
1 2 3 4 5 6 7 8 9 10 | |
Now, we have a sum of all these things and we want to find the value of the favorite sock. We can unbind it from the sum by xor multiplying the favorite-sock hypervector x. Because of the property that xor multiplication both distributes and cancels itself out.
1
| |
We can compare the result with the known values and find the closest match.
1 2 3 4 5 6 7 | |
Conclusion
We have seen that the nature of higher dimensional representation leads to some very interesting properties with both representing data and computing with it. These properties and others form the foundation of exciting advancements in Cognitive Computing like word vectors. Future posts will delve further into these interesting areas. In the meantime, I encourage you to read Kanerva’s paper on your own and to find comfort in that when you can’t find one of your socks, it’s not your fault. It most likely has something to do with the curious nature of hyperspace.
Thanks to Ross Gayler for bringing the paper to my attention and to Joe Smith for the great conversations on SDM