I wrote a blog post a while back about using a Clojure machine learning library called Cortex to do the Kaggle Cats and Dogs classification challenge.
I wanted to revisit it for a few reasons. The first one is that the Cortex library has progressed and improved considerably over the last year. It’s still not at version 1.0, but it my eyes, it’s really starting to shine. The second reason is that they recently published an example of using the RESNET50 model, (I’ll explain later on), to do fine-tuning or transfer learning. The third reason, is that there is a great new plugin for leiningen the supports using Jupyter notebooks with Clojure projects. These notebooks are a great way of doing walkthroughs and tutorials.
Putting all these things together, I felt like I was finally at a stage where I could somewhat replicate the first lesson in the Practical Deep Learning Course for Coders with Cats and Dogs - although this time all in Clojure!
Where to Start?

In the last blog post, we created our deep learning network and trained the data on scaled down images (like 50x50) from scratch. This time we are much smarter.
We are still of course going to have to get a hold of all the training data from Kaggle Cats vs Dogs Challenge. The big difference is this time, we are just going to have to train our model for 1 epoch. What’s more, the results will be way better than before.
How is this possible? We are going to use an already trained model, RESNET50. This model has already been painstakingly trained with a gigantic network that is 50 layers deep on the ImageNet challenge. That’s a challenge that has models try to classify a 1000 different categories. The theory is that the inner layers of the network have already learned about the features that make up cats and dogs, all we would need to do is peel off the final layer of the network and graft on a new layers that just learns the final classification for our 2 categories of cats and dogs. This is called transfer learning or retraining.
Plan of Action
- Get all the cats and dogs pictures in the right directory format for training
- Train the model with all but the last layer in the RESNET model. The last layer we are going to replace with our own layer that will finetune it to classify only cats and dogs
- Run the test data and come up with a spreadsheet of results to submit to Kaggle.
Getting all the data pictures in the right format
This is the generally the most time consuming step of most deep learning. I’ll spare you the gritty details but we want to get all the pictures from the train.zip into the format
-data
-cats-dogs-training
-cat
1110.png
...
-dog
12416.png
...
-cats-dogs-testing
-cat
11.png
...
-dog
12.png
...
The image sizes must also all be resized to match the input of the RESNET50. That means they all have to be 224x224.
Train the model
The cortex functions allow you to load the resnet50 model, remove the last layer, freeze all the other layers so that they will not be retrained, and add new layers.
I was surprised that I could actually train the model with all the images at 224x244 with the huge RESNET50 model. I built the uberjar and ran it which helped the performance.
lein uberjar
java -jar target/cats-dogs-cortex-redux.jar
Training one epoch took me approximately 6 minutes. Not bad, especially considering that’s all the training I really needed to do.
Loss for epoch 1: (current) 0.05875186542016347 (best) null
Saving network to trained-network.nippy
The key point is that it saved the fine tuned network to trained-network.nippy
Run the Kaggle test results and submit the results
You will need to do a bit more setup for this. First, you need to get the Kaggle test images for classification. There are 12500 of these in the test.zip file from the site. Under the data directory, create a new directory called kaggle-test. Now unzip the contents of test.zip inside that folder. The full directory with all the test images should now be:
data/kaggle-test/test
This step takes a long time and you might have to tweak the batch size again depending on your memory. There are 12500 predications to be made. The main logic for this is in function called (kaggle-results batch-size). It will take a long time to run. It will print the results as it goes along to the kaggle-results.csv file. If you want to check progress you can do wc -l kaggle-results.csv
For me locally, with (cats-dogs/kaggle-results 100) it took me 28 minutes locally.
Compare the results
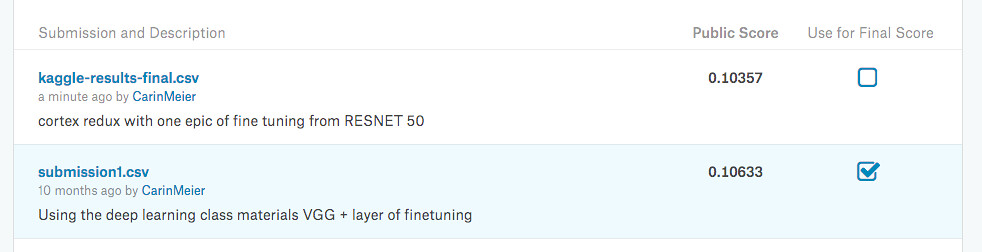
My one epoch of fine tuning beat my best results of going through the Practical Deep Learning exercise with the fine tuning the VGG16 model. Not bad at all.
Summary
For those of you that are interested in checking out the code, it’s out there on github
Even more exciting, there is a walkthrough in a jupyter notebook with a lein-jupyter plugin.
The Deep Learning world in Clojure is an exciting place to be and gaining tools and traction more and more.